

Vision
We can access, anytime and anywhere, facts and other knowledge we deem useful
in our personal and professional lives. A personalized repository organizes
information that interests us, keeps track of how we access that information,
and contains annotations about its relevance, quality, and comprehensibility.
We access our repositories in our own way. When we want more information, we
can access repositories that trusted friends and associates are willing to
share. By interacting with them, we leverage not only their own information,
but also their knowledge of what interests us. When we want still more
information, we can access widely available knowledge, for example, in
libraries or on the Web.
We can ask for "the fat book on computers I skimmed last week." We will get different responses to a query about "apples" if we are computer scientists, farmers, or in the process of filling out a grocery list. We do not get the same undesirable results each time we search the Web for a particular topic.
Approach
The individualized knowledge access subsystem supports the natural ways people
use to access information. In particular, it supports personalized,
collaborative, and communal knowledge, "triangulating" among these three
sources of information to find the information people need. It observes and
adapts to its users, so as to better meet their needs. The subsystem
integrates the following components to gather and store data, to monitor user
access patterns, and to answer queries and interpret data.
Data representation. The subsystem stores information encountered by its users using an extensible data model that links arbitrary objects via arbitrarily named arcs. There are no restrictions on object types or names. Users and the system alike can aggregate useful information regardless of its form (text, speech, images, video). The arcs, which are also objects, represent relational (database-type) information as well as associative (hypertext-like) linkage. For example, objects and arcs in A's data model can represent B's knowledge of interest to A—and vice versa.
Data acquisition. The subsystem gathers as much information as possible about the information of interest to a user. It does so through raw acquisition of data objects, by analyzing the acquired information, by observing people's use of it, by encouraging direct human input, and by tuning access to the user.
Automatic access methods. The arrival of new data triggers automated services, which, in turn, obtain further data or trigger other services. Automatic services fetch web pages, extract text from postscript documents, identify authors and titles in a document, recognize pairs of similar documents, and create document summaries that can be displayed as a result of a query. The system allows users to script and add more services, as they are needed.
Human access methods. Since automated services can go only so far in carrying out these tasks, the system allows users to provide higher quality annotations on the information they are using, via text, speech, and other human interaction modalities.
Automated observers. Subsystems watch the queries that users make, the results they dwell upon, the files they edit, the mail they send and receive, the documents they read, and the information they save. The system exploits observations of query behavior by converting query results into objects that can be annotated further. New observers can be added to exploit additional opportunities. In all cases, the observations are used to tune the data representation according to usage patterns.
Oxygen Today
 Haystack is a platform for creating,
organizing and visualizing personal information. It uses RDF as its primary
data modeling framework. Haystack makes it easy for users to manage documents,
e-mail messages, appointments, tasks, and other information. It provides
maximum flexibility in describing and organizing data, the freedom to group
related items together (regardless of the programs used to edit the items),
ease in manipulating and visualizing information in ways appropriate to the
task at hand, and the ability to delegate tasks to agents. (David Karger, Theory of Computation)
Haystack is a platform for creating,
organizing and visualizing personal information. It uses RDF as its primary
data modeling framework. Haystack makes it easy for users to manage documents,
e-mail messages, appointments, tasks, and other information. It provides
maximum flexibility in describing and organizing data, the freedom to group
related items together (regardless of the programs used to edit the items),
ease in manipulating and visualizing information in ways appropriate to the
task at hand, and the ability to delegate tasks to agents. (David Karger, Theory of Computation)
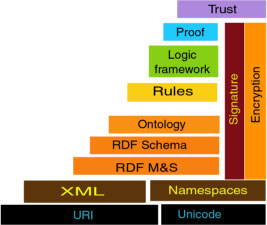 The Semantic Web is an extension of
the current Web in which information is given a well-defined meaning, better
enabling computers and people to work in cooperation. Data on the Web is
defined and linked in a way that it can be used for more effective discovery,
automation, integration, and reuse across various applications. The Semantic
Web Activity is an initiative of the World Wide Web Consortium (W3C), with the
goal of extending the current Web to facilitate Web automation, universally
accessible content, and the 'Web of Trust'. (Tim Berners-Lee, Eric Miller, World Wide Web Consortium)
The Semantic Web is an extension of
the current Web in which information is given a well-defined meaning, better
enabling computers and people to work in cooperation. Data on the Web is
defined and linked in a way that it can be used for more effective discovery,
automation, integration, and reuse across various applications. The Semantic
Web Activity is an initiative of the World Wide Web Consortium (W3C), with the
goal of extending the current Web to facilitate Web automation, universally
accessible content, and the 'Web of Trust'. (Tim Berners-Lee, Eric Miller, World Wide Web Consortium)
START is a natural language question answering system that provides untrained users with speedy access to knowledge. START parses incoming questions, matches them against its knowledge base, and presents the appropriate information segments to the user. START's knowledge base contains text (automatically annotated by a preprocessor that detects context-independent linguistic structures), images (annotated by hand), and databases. START uses Omnibase, a universal data source interface, to help it parse queries containing database attributes and their values. (Boris Katz, InfoLab Group)
