

Vision
Humans communicate with computers, in much the same way they communicate with
one another, using speech to create, access, and manage information and to
solve problems. They ask for documents and information (e.g., "Show me John's
home page" or "Will it rain tomorrow in Seattle"), without having to know where
and how the information is stored, that is, without having to remember a URL,
search through the Web for a pointer to a document, or use keyword search
engines. They specify natural constraints on the information they want (e.g.,
"I want to fly from Boston to Hong Kong with a stopover in Tokyo" or "Find me a
hotel in Boston with a pool and a Jacuzzi"), without having to step through
fixed sets of choices offered by rigid, preconceived indexing and command
hierarchies.
Users and machines engage in spontaneous, interactive conversations, arriving incrementally at the desired information in a small number of steps. Neither requires substantial training, a highly restricted vocabulary, unnatural pauses between words, or ideal acoustic conditions. By shifting the paradigm of interacting with computation to a perceptual one, spoken language understanding frees the user's limited cognitive capacities to deal with other more interesting and pressing matters.
Approach
The spoken language subsystem provides a number of limited-domain interfaces,
as well as mechanisms for users to navigate effortlessly from one domain to
another. Thus, for example, a user can inquire about flights and hotel
information when planning a trip, then switch seamlessly to obtaining weather
and tourist information. The spoken language subsystem stitches together a set
of useful domains, thereby providing a virtual, broad-domain quilt that
satisfies the needs of many users most of the time. Although the system can
interact with users in real-time, users can also delegate tasks for the system
to perform offline.
The spoken language subsystem is an integral part of Oxygen's infrastructure, not just a set of applications or external interfaces. Four components, with well-defined interfaces, interact with each other and with Oxygen's device, network, and knowledge access technologies to provide real-time conversational capabilities.
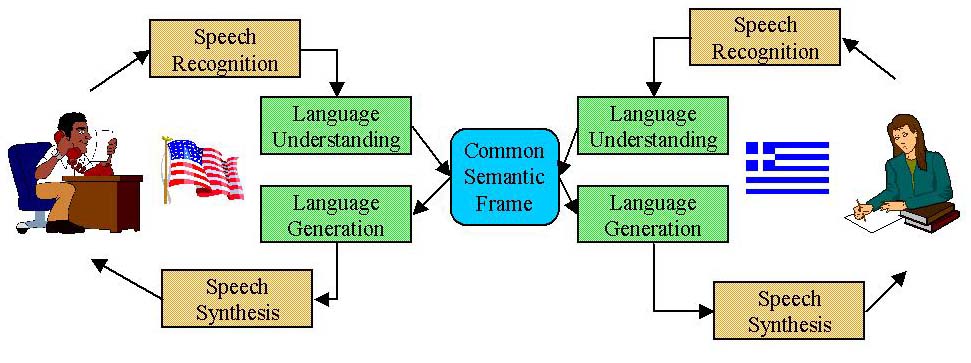
Speech recognition
The speech recognition component converts the user's speech into a sentence of
distinct words, by matching acoustic signals against a library of
phonemes—irreducible units of sound that make up a word. The component
delivers a ranked list of candidate sentences, either to the
language-understanding component or directly to an application. This component
uses acoustic processing (e.g., embedded microphone arrays), visual clues, and
application-supplied vocabularies to improve its performance.
Language understanding
The language understanding-component breaks down recognized sequences of words
grammatically, and it systematically represents their meaning. The component
is easy to customize, thereby easing integration into applications. It
generates limited-domain vocabularies and grammars from application-supplied
examples, and it uses these vocabularies and grammars to transform spoken input
into a stream of commands for delivery to the application. It also improves
language understanding by listening throughout a conversation—not just to
explicit commands—and remembering what has been said.
Lite speech systems, with user-defined vocabularies and actions, can be tailored quickly to specific applications and integrated with other parts of the Oxygen system in a modular fashion.
Language generation
The language generation component builds sentences that present
application-generated data in the user's preferred language.
Speech synthesis
A commercial speech synthesizer converts sentences, obtained either from the
language generation component or directly from the application, into speech.
Oxygen Today
Conversational system architecture
Galaxy is
an architecture for integrating speech technologies to create conversational
spoken language systems. Its central programmable Hub controls the flow of
data between various clients and servers, retaining the state and history of
the current conversation. Users communicate with Galaxy through lightweight
clients. Specialized servers handle computationally expensive tasks. In a
typical interaction, the SUMMIT
speech recognizer transforms a user utterance into candidate text strings, from
which the TINA natural
language component selects a preferred candidate and extracts its semantic
content. The dialog
manager analyzes the semantic content, using context to complete or
disambiguate the input content, and formulates the semantic content for an
appropriate response (e.g., by querying a database). Then the GENESIS
language generation system transforms the semantic content of the response into
a natural language text string, from which the ENVOICE
system synthesizes a spoken response by concatenating prerecorded segments of
speech.
Multilingual and multidomain conversational systems execute different language and domain dependent recognizers in parallel. For example, a system running multiple applications, each with its own recognizer, can perform simultaneous speech recognition and language identification, allowing users to speak to the system in any of the system's languages without having to specify which one in advance.
SpeechBuilder allows people unfamiliar with speech and language processing
to create their own speech-based applications. Developers use a simple
web-based interface to describe the important semantic concepts (e.g., objects
and attributes) for their application and show, via sample sentences, what
kinds of actions (e.g., database or CGI queries) their application can perform.
SpeechBuilder then uses this information automatically to create a
conversational interface to the application.
Applications
Spoken language interfaces provide telephone access to useful information. Jupiter
provides up-to-date information about the weather. Mercury
enables people to obtain schedules and fares for airline flights. Pegasus
provides the status of current flights (arrival and departure times and gates).
Voyager
provides tourist and travel information in the Greater Boston area.
Orion is a conversational agent that performs off-line tasks and contacts the user later, at a pre-negotiated time, to deliver timely information. Users can ask Orion to playback a recorded message ("call me tomorrow at six pm and remind me to pick up the clothes at the cleaners") or to inform them when a particular event occurs ("call me a hour before flight 32 arrives"). In the latter case, Orion interacts with an appropriate domain expert to detect when the event occurs.
(Jim Glass, Stephanie Seneff, Victor Zue,
Spoken Language
Systems)
